Créée en 2013, Robin.io est spécialisée dans l’automatisation des flux de données et des applications demandant beaucoup de ressources réseau dans les environnements Kubernetes.
Nous avions déjà rencontré Robin.io lors du dernier Virtual Tour en juin dernier. Basée à San José en Californie, la société se positionne à l'intersection de deux marchés importants, les applications Cloud natives et la 5G pour un marché adressable de 30 milliards de dollars. SAP, BNP Paribas ou Rakuten sont clients de Robin.io. La société a déjà déposé plus de 65 brevets dont plus de 50 % sont reconnus. Un des cas d'usage de la solution est le stockage des données pour les applications "stateful" dans les environnements Kubernetes. Un agent léger s'installe sur les différentes versions de Kubernetes découvre les disques présents et les regroupe dans des pools de ressources.
Robin.io propose une plate-forme nativement Cloud embarquant de nombreuses fonctions d’automatisation comme le déploiement, la mise à niveau et le cycle de vie des fonctions cloud native et virtuelle dans le réseau en s’appuyant sur Kubernetes. Le second composant de la solution est une plate-forme d’automatisation sur un multi cluster qui écrit et exécute des méthodes de procédures à l'échelle ou des workflows avec de nombreuses étapes complexes. Ces opérations peuvent se réaliser sur des multi clusters et sur différents sites (station de base, Edge, cœur de réseau) pour différents cas d’usage comme de fournir des services de Bare Metal à l’usage, la gestion des méthodes de procédures ou des accès à des services radio sous forme de services (RAN as a Service ou RaaS).
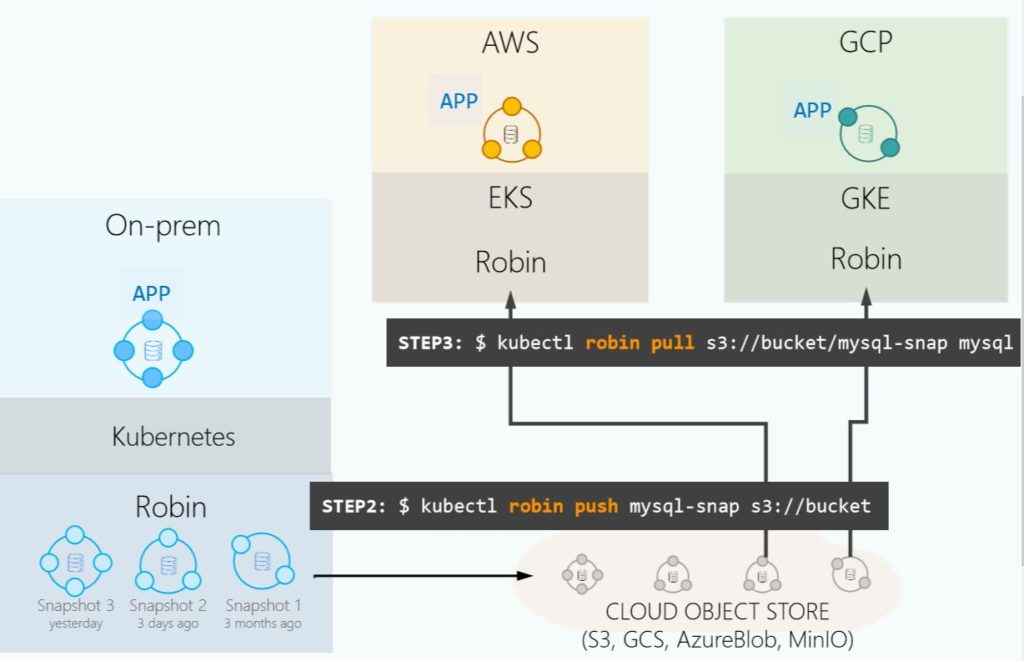
En termes de fonction, la réplication est strictement consistante et une fonction de resynchronisation automatique est présente en cas de retard. La solution intègre un placement automatique des données selon différents critères comme l'affinité des données. Pour la performance, robin.io annonce des performances comparables à celles obtenues dans des environnements Bare Metal avec un rééquilibrage des données pour éviter des encombrements en I/O. Par la console il est possible de gérer finement la capacité à la hausse ou à la baisse avec la possibilité d'adapter la taille des volumes. Les services de données sont complets : snapshots, rollback, restauration, backup, continuité et portabilité des applications.
Depuis notre dernière visite, les améliorations sont principalement commerciales avec désormais une version totalement gratuite à vie dans la limite de 5 noeuds et 10 To de stockage. La solution est de plus disponible depuis peu sur la place de marché de Red Hat pour OpenShift.
